|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
Механизмы хранения это компоненты MySQL, которые обрабатывают операции SQL
для различных табличных типов. MySQL Server использует сменную архитектуру механизма хранения, которая
позволяет механизмам хранения быть загруженными, не прерывая работу. Чтобы определить который механизмы хранения Ваш сервер поддерживает,
используйте запрос Для информации о поддержке механизма хранения, предлагаемых в коммерческих
версиях MySQL Server, см.
MySQL Enterprise Server 5.7 на Web-сайте MySQL.
Доступные механизмы хранения могут зависеть от версии Enterprise Server. Для ответов на обычно задаваемые вопросы о механизмах хранения MySQL см.
раздел A.2. Вы не ограничены использованием того же самого механизма хранения для
всего сервера или схемы. Вы можете определить механизм хранения для любой
таблицы. Например, приложение могло бы использовать главным образом
Выбор механизма хранения Различные механизмы хранения, предоставленные MySQL, разработаны для
различных случаев использования. Следующая таблица обеспечивает краткий обзор
некоторых механизмов хранения, предоставленных MySQL: Таблица 17.1.
Обзор особенностей механизмов хранения Поддержка InnoDB индексации геоданных доступна в MySQL 5.7.5 и выше.
InnoDB использует хеш-индекс внутренне для своего адаптивного хеша.
InnoDB Поддержка InnoDB FULLTEXT индексов доступна в MySQL 5.6.4 и выше.
Сжатые таблицы MyISAM поддержаны только, используя сжатый формат строки.
Таблицы, используя сжатый формат строки MyISAM, доступны только для чтения.
Сжатые таблицы InnoDB требуют формата файла InnoDB Barracuda. Шифрование табличного пространства данных доступно в MySQL 5.7 и выше.
Когда Вы составляете новую таблицу, Вы можете определить, который механизм
хранения использовать, добавляя табличную опцию Вы можете установить механизм хранения по умолчанию для текущего сеанса,
устанавливая переменную
Чтобы преобразовать таблицу из одного механизма хранения в другой,
используйте Если Вы пытаетесь использовать механизм хранения, который не собран в
двоичный модуль или собран, но дезактивирован, MySQL вместо этого составляет
таблицу, используя механизм хранения по умолчанию. Например, в установке
релпикации Ваш главный сервер использует По умолчанию предупреждение произведено всякий раз, когда
MySQL может сохранить таблицу, индексы и данные в одном или более
файлах, в зависимости от механизма хранения. Таблица и определения столбца
сохранены в словаре данных MySQL. Отдельные механизмы хранения создают любые
дополнительные файлы, требуемые для таблиц, которыми они управляют. Если имя
таблицы содержит специальные символы, названия табличных файлов содержат
закодированные версии тех символов, как описано в
разделе 10.2.3. Таблица 17.2. Особенности механизма
хранения Каждая таблица Чтобы определить явно, что Вы хотите получить таблицу Вы можете проверить или восстановить таблицы В MySQL 8.0 механизм хранения У таблиц Все значения данных сохранены с младшим байтом сначала. Это делает
данные независимыми от операционной системы и машины. Единственные требования
для двоичной мобильности: машина использует целые числа со знаком и формат
IEEE floating-point. Эти требования широко используются среди господствующих
машин. Совместимость на уровне двоичных кодов не может быть применимой к
встроенным системам, у которых иногда есть специфические процессоры. Нет никакой существенной потери скорости за хранение младшего байта данных
сначала: байты в строке таблицы обычно не выравниваются, и требуется немного
больше обработки, чтобы считать не выровненный байт в прямом порядке, чем в
обратном. Кроме того, код в сервере, который приносит значения столбцов, не
срочен по сравнению с другим кодом. Максимальное количество столбцов в индексе 16. Поддержка настоящего типа Форум, посвященный механизму хранения Следующие опции mysqld
могут использоваться, чтобы изменить поведение таблиц
Таблица 17.3. Обзор опций и
переменных Установить режим автоматического восстановления разрушенных таблиц
Не сбрасывать ключевые буферы между записями для любой таблицы
Если Вы делаете это, Вы не должны получить доступ к таблицам
Следующие системные переменные затрагивают поведение таблиц
Размер кэша, используемого в оптимизации вставок оптом. Это предел на поток! Максимальный размер временного файла, который MySQL разрешают
использовать, обновляя индекс Установить размер буфера, используемого для восстановления таблиц.
Автоматическое восстановление активировано, если Вы запускаете
mysqld с
опцией Сервер проверяет таблицу на ошибки. Если восстановление не в состоянии возвратить все строки ранее завершенных
запросов, и Вы не определяли Таблицы Строковые индексы сжимают пробелы. Если первая часть индекса строка,
префикс также сжат. Сжатие пространства делает индексный файл меньшим, чем
число худшего случая, если строковый столбец имеет большой конечный пробел
или есть столбец В таблицах Когда Вы используете См. раздел 14.1.15 для информации о
Вы можете распаковать сжатые таблицы Статический формат значение по умолчанию для таблицы Из трех форматов хранения Формат строки фиксированной длины доступен только для таблиц без столбцов
У таблиц статического формата есть эти характеристики: Столбцы Динамический формат хранения используется, если таблица
Динамический формат немного более сложен, чем статический формат, потому
что у каждой строки есть заголовок, который указывает, какой она длины.
Строка может стать фрагментированной (сохраненной в частях, состоящих из
нескольких несмежных участков), когда она сделана более
длинной в результате обновления. Вы можете использовать У таблиц динамического формата есть эти характеристики: Все строковые столбцы являются динамическими кроме тех, чья
длина меньше четырех. Сжатый формат хранения это формат только для чтения, который произведен с
помощью myisampack
. Сжатые таблицы могут быть рассжаты с помощью
myisamchk.
У сжатых таблиц есть следующие характеристики: Сжатые таблицы берут очень немного дискового пространства. Это
минимизирует дисковое использование, что полезно, используя медленные диски
(такие как CD-ROM). Сжатие пространства суффикса. Может использоваться для строк фиксированной или динамической длины.
В то время как сжатая таблица только для чтения, и Вы не можете поэтому
обновить или добавить строки в таблице, операции DDL (язык определения
данных) все еще допустимы. Например, Вы все еще можете использовать
Формат файла, применяемый MySQL, чтобы хранить данные был экстенсивно
проверено, но всегда есть обстоятельства, которые могут заставить таблицы
базы данных становиться поврежденными. Следующее обсуждение описывает, как
это может произойти и как обработать ситуацию. Даже при том, что формат таблицы Процесс mysqld
грохнулся в середине записи. Типичные признаки поврежденной таблицы: Вы получаете следующую ошибку, выбирая данные из таблицы:
Запросы не находят строки в таблице или
возвращают неполные результаты. Вы можете проверить здоровье таблицы Если Ваши таблицы становятся поврежденными часто, Вы должны попытаться
определить, почему это происходит. Самая важная вещь состоит в том, стала ли
таблица поврежденной в результате катастрофического отказа сервера. Вы можете
проверить это легко, ища недавнее сообщение Каждый индексный файл Счетчик работает следующим образом: В первый раз, когда таблица обновлена в MySQL, счетчик в заголовке
индексных файлов постепенно увеличен. Другими словами, счетчик может стать неправильным только
при этих условиях: Таблица Вообще, плохая идея совместно использовать каталог данных несколькими
серверами. См. раздел 6.7.
Механизм хранения Таблица 17.4. Особенности механизма
хранения Когда использовать MEMORY
или MySQL Cluster. Разработчики приложений, которые используют механизм
хранения Операции, вовлекающие переходные, некритические данные, такие как
управление сеансом или кэширование. Когда сервер MySQL перезапускается,
данные в таблицах MySQL Cluster предлагает те же самые особенности как механизм
Блокировка на уровне строки и работа многих потоков. Для отчета с более подробным сравнением механизмов хранения
Таблицы Работа Несмотря на обработку в памяти для таблиц В зависимости от видов запросов, выполненных на таблицах
Механизм хранения У Место для таблиц Чтобы создать таблицу Этот пример показывает, как Вы могли бы создать, использовать и
удалить таблицу Механизм хранения Таблицы Если табличный хеш индекс имеет высокую степень ключевого дублирования
(многие индексные записи содержат то же самое значение), обновления таблицы,
которые затрагивают значения ключа и все удаления значительно медленнее.
Степень этого замедления пропорциональна степени дублирования (или обратно
пропорциональна количеству элементов). Вы можете использовать индекс
У таблиц Столбцы, которые индексированы, могут содержать значения Табличное содержание Если внутренняя временная таблица становится слишком большой,
сервер автоматически преобразовывает ее в хранение на диске, как описано в
разделе 9.4.4. Чтобы заполнить таблицу Таблицы Сервер нуждается в достаточной памяти, чтобы поддержать все таблицы
Память не восстановлена, если Вы удаляете отдельные строки из таблицы.
Память восстановлена только, когда вся таблица удалена. Память, которая ранее
использовалась для удаленных строк, снова будет использована для новых строк
в пределах той же самой таблицы. Чтобы освободить всю память, используемую
таблицей, когда Вы больше не требуете ее содержания, выполните
Память, необходимая для одной строки в таблице Как упомянуто ранее, переменная
Вы можете также определить табличную опцию Форум, посвященный механизму хранения Механизм хранения Механизм хранения Чтобы исследовать механизм Когда Вы создаете таблицу Если Вы исследуете файл Механизм хранения CSV поддерживает Запрос Во время ремонта только строки из файла CSV до первой поврежденной строки
скопированы к новой таблице. Все другие строки от первой поврежденной строки
до конца таблицы удалены, даже допустимые строки. Механизм хранения Механизм хранения Все таблицы, которые Вы создаете с использованием механизма хранения
Механизм хранения Таблица 17.5. Особенности механизма
хранения Механизм хранения Исходные тексты механизма Когда Вы создаете таблицу Механизм Механизм Механизм Механизм Хранение: Строки сжаты, когда они вставлены.
Извлечение: при извлечении строки рассжаты
по требованию, нет никакого кэша строки. Форум, посвященный механизму хранения Механизм хранения Механизм Когда Вы создаете таблицу Механизм хранения Механизм хранения Вы можете проверить доступен ли механизм хранения Вставки в таблицу Используя основанное на строке двоичное журналирование, обновления и
удаления пропущены, но не зарегистрированы и не применены. Поэтому Вы должны
использовать STATEMENT для формата двоичного журналирования, а не
ROW или MIXED. Предположите, что Ваше приложение требует, чтобы ведомая сторона
применяла правила фильтрации, но передача всех двоичных данные журнала
ведомому устройству привела к слишком большому количеству трафика. В таком
случае возможно настроить на ведущем узле пустой
ведомый процесс, механизм хранения по умолчанию которого
Ведущее устройство пишет двоичный журнал. Пустой
процесс mysqld
обрабатывает действия как ведомое устройство, применяя желаемую
комбинацию правил Фиктивный процесс фактически не хранит данных, таким образом есть
небольшая обработка, выполняя дополнительный процесс
mysqld на
ведущем узле. Этот тип установки может быть повторен с дополнительными
ведомыми устройствами репликации. Триггеры Другие возможные применения для механизма
хранения Проверка синтаксиса файла дампа. Механизм Механизм Blackhole и столбцы Auto Increment:
Механизм Blackhole пустой. Любые операции, выполненные на табличном
использовании Blackhole не будут иметь никакого эффекта. Это должно быть в
памяти, рассматривая поведение столбцов первичного ключа, имеющих auto
increment. Механизм не будет автоматически постепенно увеличивать значения
полей и не сохраняет статус полей auto increment.
У этого есть важные значения в репликации. Рассмотрите следующий сценарий, где все три из
следующих условий применяются: На главном сервере есть blackhole таблица с полем auto
increment, которое является первичным ключом. В этом сценарии репликация потерпит неудачу с ошибкой дублирования записи
на столбце первичного ключа. При репликации на основе запроса значение При репликации на основе строки значение, которое механизм возвращает для
строки, всегда будет тем же самым для каждой вставкт. Это приведет к ведомому
устройству, пытающемуся переигрывать две записи журнала о вставке, используя
то же самое значение для столбца первичного ключа, таким образом,
репликация потерпит неудачу. Фильтрация столбца При репликации на основе строки
( Эта фильтрация работает на ведомой стороне, то есть, столбцы скопированы
ведомому устройству прежде, чем они будут отфильтрованы. Есть по крайней мере
два случая, где нежелательно скопировать столбцы к ведомому устройству: Если данные являются конфиденциальными, таким образом, у
ведомого сервера не должно быть доступа к ним. Основная фильтрация столбца может быть достигнута, используя
Установка для ведущего устройства:
Механизм хранения Альтернатива таблице Когда Вы создаете таблицу Вы можете использовать Использование таблицы Использование Чтобы создать таблицу Следующий пример показывает, как создать таблицу После создания таблицы Также возможно использовать Основные табличные определения и индексы должны соответствовать близко
определению У таблицы должно быть то же самое число столбцов. Тип столбца в основной таблице и Основная таблица должна иметь, по крайней мере, столько индексов,
сколько Известная проблема существует: индексы на тех же самых столбцах должны
быть в идентичном порядке в таблицах Каждый индекс должен удовлетворить эти проверки: Тип индекса основной таблицы и Длины частей индекса должны быть равны. Если таблица Форум, посвященный механизму хранения Таблицы Легко управлять рядом таблиц журнала. Например, Вы можете
поместить данные с различных месяцев в отдельные таблицы, сжать некоторых из
них myisampack
, а затем создать таблицу Недостатки Вы можете использовать только идентичные
Следующее известные проблемы с таблицами В версиях сервера MySQL до 5.1.23 было возможно составить
временные таблицы С версии 5.1.23 MERGE заблокированы через родительскую таблицу. Если
родитель был временным, это не было заблокировано и таким образом, дочерние
элементы не были заблокированы также. Параллельное использование таблиц
MyISAM повреждает их. Подобные соображения применимы к
Неожиданные результаты включают возможность того, что работа на таблице
Механизм хранения Чтобы включить механизм хранения Механизм хранения Исходный текст механизма Когда Вы составляете таблицу, используя один из стандартных механизмов
хранения (такой как Таблица Удаленный сервер с таблицей базы данных,
которая в свою очередь состоит из табличного определения (сохраненного в
словаре данных MySQL) и связанной таблицы. Табличный тип отдаленной таблицы
может быть любым типом, поддержанным отдаленным сервером Выполняя запросы к таблице Базовая структура таблицы Рис. 17.1. Структура
таблицы FEDERATED Когда клиент делает запрос SQL, который обращается к таблице
Механизм хранения просматривает каждый столбец таблицы
Локальный сервер сообщает с использованием удаленного сервера MySQL C API.
Это вызывает Чтобы создать таблицу Составьте таблицу на удаленном сервере. Альтернативно,
обратите внимание на табличное определение существующей таблицы, возможно,
используя
Например, Вы могли бы составить следующую таблицу на удаленном сервере:
Когда Вы составляете местную таблицу, у нее должно
быть определение, идентичное отдаленной таблице. Вы можете улучшить исполнение таблицы Чтобы использовать первый метод, Вы должны определить строку
Строка Формат строки подключения:
Типовые строки подключения:
Если Вы создаете много таблиц Формат Например, чтобы создать соединение сервера, идентичное строке
The Вы должны знать о следующих моментах, используя
механизм хранения Таблицы Следующие элементы указывают на особенности
механизма хранения Удаленный сервер должен быть сервером MySQL. Запросы, которые не в состоянии использовать индексы, могут таким образом
вызвать низкую производительность и сетевую перегрузку. Кроме того, так как
возвращенные строки должны быть сохранены в памяти, такой запрос может также
привести к свопингу или даже зависанию локального сервера. Размер вставки не может превысить максимальный пакетный размер
обмена между серверами. Если вставка превышает этот размер, она поделена на
много пакетов, и проблема с отменой транзакции может произойти. Нет никакого пути у механизма Дополнительные ресурсы доступны для Форум, посвященный механизму хранения Механизм хранения Чтобы включить механизм хранения Исходные тексты механизма хранения Когда Вы создаете Другие механизмы хранения могут быть доступными от третьих сторон и членов
сообщества, которые использовали интерфейс Custom Storage Engine. Сторонние механизмы не поддержаны MySQL. Для дополнительной информации,
документации, инструкций по установке, сообщений об ошибках или для любой
справки или помощи с этими механизмами, пожалуйста, свяжитесь с
разработчиком механизма непосредственно. Для получения дополнительной информации о развитии потребительского
механизма хранения, который может использоваться с Pluggable Storage
Engine Architecture, см.
MySQL Internals: Writing a Custom Storage Engine. Архитектура подключаемого механизма хранения MySQL позволяет профессионалу
базы данных выбрать специализированный механизм хранения для особой
потребности приложения, будучи полностью свободным от того, чтобы управлять
любым определенным приложением, кодирующим требования. Архитектура сервера
MySQL изолирует программиста приложения и DBA от всех низкоуровневых деталей
выполнения на уровне хранения, обеспечивая последовательную и легкую модель
приложения и API. Таким образом, хотя есть различные способности у разных
механизмов хранения, приложение экранировано от этих различий. Подключаемыя архитектура механизма хранения обеспечивает стандартный набор
методов управления и поддержки, который распространен среди всех основных
механизмов хранения. Механизмы самого хранения это компоненты сервера базы
данных, которые фактически выполняют действия на основных данных, которые
поддержаны на уровне физического сервера. Эта эффективная и модульная архитектура обеспечивает огромные возможности
для тех приложений, которые определенно предназначаются для особых задач.
Таких, как складирование данных, обработка транзакций или высокая
доступность, обладая преимуществом использования ряда интерфейсов и служб,
которые независимы от любого механизма хранения. Программист приложения и DBA взаимодействуют с базой данных MySQL через
Connector API и уровни служб, которые выше механизмов хранения. Если
изменения приложения вызывают требования изменений механизма хранения, или
чтобы один или более механизмов хранения были добавлены, чтобы поддержать
новые потребности, никакие существенные изменения кодирования или
процесса не нужны. Архитектура сервера MySQL экранирует приложение от
основной сложности механизма хранения, представляя последовательный и удобный
в работе API, который применяется через механизмы хранения. MySQL Server использует подключаемую архитектуру механизма хранения,
которая позволяет механизмам хранения быть загруженными в сервер. Включение механизма хранения Прежде, чем механизм хранения сможет использоваться, совместно
использованная библиотека плагина механизма хранения должна быть загружена в
MySQL, используя Совместно используемая библиотека должна быть расположена в каталоге
плагинов сервера MySQL, местоположение которого дано переменной
Отключение механизма хранения Чтобы отключить механизм хранения, используйте
Подключаемый механизм хранения MySQL является компонентом в сервере базы
данных MySQL, который ответственен за то, что выполняет фактические операции
ввода/вывода для базы данных так же, как реализует определенные наборы
функций, которые предназначаются для определенной потребности приложения.
Главная выгода использования механизмов хранения: Вам поставляют только
особенности, необходимые для особого приложения, поэтому у Вас есть меньше
затрат с более эффективным конечным результатом С технической точки зрения, каковы некоторые из уникальных компонентов
инфраструктуры поддержки, которые находятся в механизме хранения? Некоторые
из особенностей включают: Параллелизм: У некоторых приложений есть
больше гранулированных требований блокировки (таких, как блокировки на уровне
строки), чем у других. Выбор правильной стратегии блокировки может уменьшить
издержки и поэтому улучшить эффективность работы. Эта область также включает
поддержку таких способностей, как управление параллелизмом мультивариантов
или чтение снимков. Каждый набор подключаемых компонентов инфраструктуры механизма хранения
разработан, чтобы предложить набор выгод для особого приложения. Наоборот,
уход от ряда составляющих особенностей помогает уменьшить ненужные затраты.
Надо понимать, что понимание набора требований приложения и выбор надлежащего
механизма хранения MySQL могут оказать драматическое влияние на
полную системную эффективность.
Глава 17. Механизмы хранения
InnoDB
механизм хранения общего назначения по умолчанию, Oracle рекомендует
использовать это для таблиц за исключением специализированных случаев
использования. Запрос CREATE TABLE
в MySQL 8.0 создает таблицы InnoDB по умолчанию.SHOW ENGINES
. Значение в столбце Support указывает, может ли механизм
использоваться. Значения YES, NO или
DEFAULT указывают, что механизм доступен, не доступен или
доступен и в настоящее время установлен как механизм хранения по умолчанию.
mysql> SHOW ENGINES\G
*************************** 1. row ***************************
Engine: PERFORMANCE_SCHEMA
Support: YES
Comment: Performance Schema
Транзакции: NO
XA: NO
Savepoints: NO
*************************** 2. row ***************************
Engine: InnoDB
Support: DEFAULT
Comment: Supports Транзакции, row-level locking, and foreign keys
Транзакции: YES
XA: YES
Savepoints: YES
*************************** 3. row ***************************
Engine: MRG_MYISAM
Support: YES
Comment: Collection of identical MyISAM tables
Транзакции: NO
XA: NO
Savepoints: NO
*************************** 4. row ***************************
Engine: BLACKHOLE
Support: YES
Comment: /dev/null storage engine (anything you write to it disappears)
Транзакции: NO
XA: NO
Savepoints: NO
*************************** 5. row ***************************
Engine: MyISAM
Support: YES
Comment: MyISAM storage engine
Транзакции: NO
XA: NO
Savepoints: NO
...
Эта глава касается случаев использования для механизмов хранения MySQL
специального назначения. Это не покрывает
InnoDB или
NDB, см. главу 16 и
MySQL Cluster NDB 7.5. Для продвинутых пользователей это
также содержит описание архитектуры механизма хранения (см.
раздел 17.11).
Поддерживаемые механизмы хранения в
MySQL 8.0
InnoDB:
Механизм хранения по умолчанию в MySQL 8.0.
InnoDB транзакционно-безопасный (соответствует ACID)
механизм хранения для MySQL, который имеет завершение и отмену транзакций,
способности восстановления катастрофического отказа и защиту пользовательских
данных. Блокировка InnoDB на уровне строки (без подъема к более
грубым блокировкам степени детализации) и последовательные чтения без
блокировки увеличивают многопользовательский параллелизм. InnoDB
хранит пользовательские данные в кластеризируемых индексах, чтобы уменьшить
ввод/вывод для общих запросов, основанных на первичных ключах. Чтобы
поддержать целостность данных, InnoDB также реализует
FOREIGN KEY ограничения справочной целостности. Для получения
дополнительной информации о InnoDB см.
главу 16.MyISAM:
У этих таблиц есть маленький след.
Блокировка на уровне таблицы
ограничивает работу в рабочих нагрузках чтения-записи, таким образом, это
часто используется только для чтения или в рабочих нагрузках чтения, главным
образом, в Сети и конфигурациях складирования данных.Memory:
Хранит все данные в RAM для быстрого доступа в среде, которая требует быстрых
поисков некритических данных. Этот механизм был прежде известен как
HEAP. Его случаи использования уменьшаются.
InnoDB с его буферным бассейном памяти обеспечивает длительный
способ сохранить больше всего или все данные в памяти, а
NDBCLUSTER обеспечивает быстрые поиски значения ключа для
огромных распределенных наборов данных.CSV:
Эти таблицы действительно текстовые файлы с отделенными запятыми значениями.
Таблицы CSV позволяют Вам импортировать или выводить данные в формате CSV,
обмениваться информациями со скриптами и приложениями, которые читают и пишут
тот же самый формат. Поскольку таблицы CSV не индексированы, Вы, как правило,
храните данные в таблицах InnoDB во время нормального
функционирования, а используете таблицы CSV только во время
импорта или экспорта.Archive:
Эти компактные, неиндексированные таблицы предназначены для хранения и
получения большого количества исторических редко ссылаемых, заархивированных
данных или информации безопасности.Blackhole:
Механизм хранения Blackhole принимает, но не хранит данные, подобно
Unix-устройству /dev/null. Запросы всегда возвращают пустой
набор. Эти таблицы могут использоваться в конфигурациях репликации, когда
запросы DML посылают в ведомые серверы, но главный сервер не сохраняет свою
собственную копию данных.Merge:
Позволяет MySQL DBA или разработчикам логически сгруппировать серию
идентичных таблиц MyISAM и ссылаться на них, как на один объект.
Хорош для среды VLDB, такой как складирование данных.Federated:
Предлагает способность соединить отдельные серверы MySQL, чтобы создать одну
логическую базу данных из многих физических серверов. Очень хорош для
распределенной среды данных.Example:
Этот механизм служит примером в исходном коде MySQL, который иллюстрирует,
как начать писать новые механизмы хранения. Это имеет прежде всего интерес
для разработчиков. Механизм хранения ничего не делает. Вы можете составить
таблицы с этим механизмом, но никакие данные не могут храниться в них или
получены от них.InnoDB с одной CSV для того, чтобы экспортировать
данные в электронную таблицу и нескольких таблиц MEMORY
для временных рабочих пространств.
Особенность MyISAM
Memory InnoDB
Archive NDB Пределы хранения 256 TB RAM
64 TB Нет 384 EB Транзакции Нет Нет Да
Нет Да Степень детализации блокировки Таблица
Таблица Строка Строка Строка MVCC Нет Нет Да Нет
Нет Картографические типы данных Да Нет
Да Да Да Картографические индексы Да Нет
Да Нет Нет Индексы B-tree Да Да Да
Нет Нет Индексы T-tree Нет Нет Нет
Нет Да Индексы Hash Нет Да Нет
Нет Да Индексы Full-text search Да Нет
Да Нет Нет Индексы Clustered Нет Нет Да
Нет Нет Кэш данных Нет N/A Да
Нет Да Кэш индекса Да N/A Да
Нет Да Сжатые данные Да Нет Да
Да Нет Зашифрованные данные Да Да
Да Да Да Поддержка базы данных кластера Нет
Нет Нет Нет Да Поддержка репликации Да Да
Да Да Да Поддержка внешнего ключа Нет Нет
Да Нет Нет Резервное копирование/восстановление момента времени
Да Да Да Да Да Поддержка кэша запроса Да Да
Да Да Да Статистика обновления для словаря данных Да
Да Да Да Да 17.1. Установка механизма хранения
ENGINE в запрос
CREATE TABLE:
-- ENGINE=INNODB not needed unless you have set a different
-- default storage engine.
CREATE TABLE t1 (i INT) ENGINE = INNODB;
-- Simple table definitions can be switched from one to another.
CREATE TABLE t2 (i INT) ENGINE = CSV;
CREATE TABLE t3 (i INT) ENGINE = MEMORY;
Когда Вы опускаете опцию ENGINE, механизм хранения по
умолчанию используется. Это InnoDB в
MySQL 8.0. Вы можете переопределить механизм по умолчанию при использовании
опции
--default-storage-engine при запуске сервера или задав опцию
default-storage-engine в конфигурационном файле my.cnf
.
default_storage_engine:
SET default_storage_engine=NDBCLUSTER;
Механизм хранения для таблиц TEMPORARY, составленных с
CREATE TEMPORARY TABLE,
может быть установлен отдельно от механизма для постоянных таблиц,
устанавливая переменную
default_tmp_storage_engine.
ALTER TABLE,
который указывает на новый механизм:
ALTER TABLE t ENGINE = InnoDB;
См. разделы 14.1.15 и
14.1.7.
InnoDB для максимальной
безопасности, но ведомые серверы используют другие механизмы хранения для
скорости за счет длительности или параллелизма.CREATE TABLE или
ALTER TABLE
не может использовать механизм хранения по умолчанию. Чтобы предотвратить
запутывающее, непреднамеренное поведение, если желаемый механизм недоступен,
включите режим SQL
NO_ENGINE_SUBSTITUTION. Если желаемый механизм недоступен, эта
установка производит ошибку вместо предупреждения, и таблица не будет
составлена или изменена. См. раздел 6.1.8.
17.2. Механизм хранения MyISAM
MyISAM основан на более старом (и больше недоступном)
механизме хранения ISAM, но есть много полезных расширений.MyISAM
Пределы хранения
256 TB Транзакции
Нет Степень детализации блокировки
Таблица MVCC Нет
Картографические типы данных
Да
Индексирование геоданных
Да Индексы B-tree
Да Индексы T-tree Нет
Индексы Hash Нет Индексы Full-text search
Да Кластеризуемые индексы
Нет Кэш данных Нет Кэш индексов
Да Сжатые данные Да
Шифрование данных Да Поддержка базы данных кластера
Нет Репликация
Да Поддержка внешнего ключа
Нет Резервное копирование/восстановление
момента времени Да Кэш запросов
Да Статистика обновления для
словаря данных Да MyISAM сохранена на диске в двух файлах. У
файлов есть имена, которые начинаются с имени таблицы и имеют расширение,
чтобы указать на тип файла. Файл с данными имеет расширение
.MYD (MYData). Индексный файл имеет расширение
.MYI (MYIndex). Табличное определение сохранено в
словаре данных MySQL.MyISAM,
укажите на это табличной опцией ENGINE:
CREATE TABLE t (i INT) ENGINE = MYISAM;
В MySQL 8.0 обычно необходимо использовать
ENGINE, чтобы определить механизм хранения MyISAM,
потому что InnoDB механизм по умолчанию.
MyISAM с помощью
mysqlcheck
или myisamchk
. Вы можете также сжать таблицы MyISAM с
myisampack
, чтобы они занимали намного меньше пространства. См. разделы
5.5.3,
5.6.4 и
5.6.6.MyISAM
не оказывает поддержки разделения. Разделенные таблицы
MyISAM, составленные в предыдущих версиях MySQL, не могут
использоваться в MySQL 8.0. Для получения дополнительной
информации см.
раздел 20.6.2. Для справки по обновлению таких таблиц так, чтобы они
могли использоваться в MySQL 8.0, см.
раздел 2.10.1.1.MyISAM есть следующие характеристики:MyISAM.MyISAM 64.
AUTO_INCREMENT), индексное дерево разделено
так, чтобы высокий узел только содержал один ключ. Это улучшает использование
пространства в индексином дереве.AUTO_INCREMENT на
таблицу реализована. MyISAM автоматически обновляет этот столбец
для INSERT и
UPDATE. Это делает столбцы
AUTO_INCREMENT быстрее (по крайней мере на 10%). Значения
наверху последовательности не использованы снова, будучи удаленными. Когда
столбец AUTO_INCREMENT определен как последний столбец индекса
из нескольких столбцов, повторное использование значений, удаленных из
вершины последовательности, действительно происходит. Значение
AUTO_INCREMENT может быть сброшено с
ALTER TABLE или
myisamchk.
MyISAM поддерживает параллельные вставки: Если у таблицы нет
никаких свободных блоков в середине файла с данными, Вы можете
INSERT новые строки в то же самое
время, когда другие потоки читают из таблицы. Свободный блок может произойти
в результате удаления строк или обновления строки динамической длины с
большим количеством данных, чем текущее содержание. Когда все свободные блоки
израсходованы (заполнены), будущие вставки снова становятся параллельными.
См. раздел 9.11.3.DATA DIRECTORY и INDEX DIRECTORY в
CREATE TABLE. См.
раздел 14.1.15.BLOB и
TEXT могут быть индексированы.NULL разрешены в индексированных столбцах. Это
берет от 0 до 1 байта на ключ.MyISAM, который указывает, была
ли таблица закрыта правильно. Если
mysqld запущен с опцией
--myisam-recover-options, таблицы MyISAM
автоматически проверены, когда открыты и восстановлены, если таблица не была
закрыта должным образом.--update-state
. myisamchk --fast
проверяет только те таблицы, у которых нет этой метки.
BLOB и
VARCHAR.MyISAM также поддерживает следующие функции:VARCHAR
: столбцы VARCHAR
начинаются с длины, сохраненной в одном или двух байтах.VARCHAR могут иметь
фиксированную или динамическую длину строки.VARCHAR и
CHAR в таблице может
составить до 64 КБ.UNIQUE.Дополнительные ресурсы
MyISAM доступен
на http://forums.mysql.com/list.php?21.17.2.1. Опции запуска MyISAM
MyISAM. Для дополнительной информации см.
раздел 6.1.4.MyISAM
Имя Cmd-Line
Файл опции Системная переменная
Статусная переменная Контекст переменной
Динамическая
bulk_insert_buffer_size
Да Да Да Оба Да
concurrent_insert Да Да Да
Глобальный Да
delay-key-write Да Да
Глобальный Да - Переменная:
delay_key_write
Да Глобальный Да
have_rtree_keys Да
Глобальный Нет
key_buffer_size Да Да Да
Глобальный Да log-isam
Да Да
myisam-block-size Да Да
myisam_data_pointer_size Да Да Да
Глобальный Да
myisam_max_sort_file_size Да Да Да
Глобальный Да
myisam_mmap_size Да Да Да
Глобальный Нет
myisam-recover-options Да Да
- Переменная:
myisam_recover_options
myisam_recover_options Да
Глобальный Нет
myisam_repair_threads Да Да Да
Оба Да
myisam_sort_buffer_size Да Да Да
Оба Да
myisam_stats_method Да Да Да
Оба Да
myisam_use_mmap Да Да Да
Глобальный Да
skip-concurrent-insert Да Да
- Переменная:
concurrent_insert
tmp_table_size
Да Да Да Оба Да
MyISAM.
--delay-key-write=ALL
MyISAM.MyISAM из другой программы (от другого сервера MySQL или с
myisamchk),
когда таблицы используются. Это несет риски повреждения индекса.
Использование
--external-locking не устраняет этот риск.MyISAM. Для дополнительной информации см.
раздел 6.1.5.MyISAM (во время
REPAIR TABLE,
ALTER TABLE или
LOAD DATA INFILE).
Если размер файла больше, чем это значение, индекс создается, используя
вместо этого ключевой кэш, который медленнее. Значение дано в байтах.
myisam_sort_buffer_size
--myisam-recover-options. В этом случае когда сервер открывает
таблицу MyISAM, он проверяет, отмечена ли таблица как
"разрушено" или не является ли переменная количества открытий для таблицы 0,
и Вы выполняете сервер с внешней отключенной блокировкой. Если любое из этих
условий истина, происходит следующее:FORCE в значении опции
--myisam-recover-options, автоматический ремонт прерывается с
сообщением об ошибке в журнале ошибок:
Error: Couldn't repair table: test.g00pages
Если Вы определяете FORCE, вместо этого будет предупреждение:
Warning: Found 344 of 354 rows when repairing ./test/g00pages
Если автоматическое значение восстановления включает BACKUP,
процесс восстановления создает файлы с названиями вида
tbl_name-datetime.BAK17.2.2. Необходимое пространство для ключей
MyISAM используют индексы B-tree.
Вы можете примерно вычислить размер для индексного файла как
(key_length+4)/0.67, суммированный по всем ключам. Это для
худшего случая, когда все ключи вставлены в сортированном порядке, и у
таблицы нет никаких сжатых ключей.VARCHAR, который
не всегда используется на всю длину. Сжатие приставки используется на ключах,
которые начинаются со строки. Сжатие приставки помогает, если есть много
строк с идентичной приставкой.MyISAM Вы можете также сжать числовые префиксы,
определяя опцию PACK_KEYS=1, когда Вы составляете таблицу. Числа
сохранены со старшим байтом сначала, таким образом, это помогает, когда у Вас
есть много ключей целого числа, у которых есть идентичный префикс.17.2.3.
Табличные форматы хранения MyISAM
MyISAM поддерживает три различных формата хранения. Два из
них, фиксрованный и динамический, выбраны автоматически в зависимости от типа
столбцов, которые Вы используете. Третий, сжатый, формат может быть создан
только с помощью myisampack
(см. раздел 5.6.6
).CREATE TABLE
или ALTER TABLE
для таблицы, которая не имеет столбцов
BLOB или
TEXT, Вы можете привести формат
таблицы к FIXED или DYNAMIC с опцией
ROW_FORMAT.ROW_FORMAT.MyISAM, используя
myisamchk--unpack, см.
раздел 5.6.4.17.2.3.1. Табличные характеристики
(фиксированная длина)
MyISAM.
Это используется, когда таблица не содержит столбцов переменной длины
(VARCHAR,
VARBINARY,
BLOB или
TEXT).
Каждая строка сохранена, используя постоянное число байтов.MyISAM статический формат является
самым простым и самым безопасным (наименьшее количество объектов). Это
является также самым быстрым из форматов на диске из-за легкости, с которой
строки в файле с данными могут быть найдены на диске: чтобы искать строку,
основываясь на номере строки в индексе, умножьте номер строки на длину
строки, чтобы вычислить позицию строки. Кроме того, просматривая таблицу,
очень легко считать постоянное число строк каждым дисковым запросом.BLOB или
TEXT. Составление таблицы с этими
столбцами с явным указанием ROW_FORMAT не будет создавать
ошибку или предупреждение, спецификация формата будет проигнорирована.CHAR и
VARCHAR дополнены пробелами до
указанной ширины столбца, хотя тип столбца не изменен. Столбцы
BINARY и
VARBINARY
дополнены байтами 0x00.NULL требуют дополнительное пространство в строке,
чтобы сделать запись, являются ли их значения NULL. Каждый
столбец NULL берет один дополнительный бит, округленный к
самому близкому байту.OPTIMIZE TABLE или
myisamchk -r
.
Длина строки = 1 + (
Сумма длин столбцов) +
(Число столбцов NULL +
delete_flag + 7)/8 +
(Число столбцов переменной длины)
delete_flag = 1 для таблиц со статическим форматом
строки. Статические таблицы используют немного места в отчете строки для
флага, который указывает, была ли строка удалена. delete_flag
= 0 для динамических таблиц, потому что флаг сохранен в
динамическом заголовке строки.17.2.3.2.
Динамические табличные характеристики
MyISAM содержит любые столбцы переменной длины
(VARCHAR,
VARBINARY,
BLOB или
TEXT) или если таблица была
составлена с опцией ROW_FORMAT=DYNAMIC.OPTIMIZE
TABLE или myisamchk
-r для дефрагментации таблицы. Если у Вас есть столбцы
фиксированной длины, к которым Вы получаете доступ или часто изменяете в
таблице, которая также содержит некоторые столбцы переменной длины, может
быть хорошей идеей переместить столбцы переменной длины в другие таблицы,
чтобы избежать фрагментации.NULL. Если у строкового столбца есть длина 0 после удаления
конечного пробела или у числового столбца есть значение 0, это отмечено в
битовом массиве и не сохранено на диске. Непустые строки сохранены как байт
длины плюс строковое содержание.NULL требуют дополнительного пространства в строке,
чтобы сделать запись, являются ли их значения NULL. Каждый
столбец NULL берет один дополнительный бит, округленный
к самому близкому байту.OPTIMIZE TABLE или
myisamchk -r
время от времени, чтобы улучшить работу. Используйте
myisamchk -ei
, чтобы получить табличную статистику.
3 + (
Есть затраты в 6 байтов для каждой ссылки. Динамическая строка получает
ссылку всякий раз, когда обновление вызывает расширение строки. Каждая новая
ссылка составляет по крайней мере 20 байтов, таким образом, следующее
расширение, вероятно, входит в ту же самую ссылку. В противном случае другая
ссылка создается. Вы можете найти число ссылок, используя
myisamchk -ed
. Все ссылки могут быть удалены с Число столбцов + 7)/8 +
(Число столбцов char) +
(Упакованный размер числовых столбцов) +
(Длина строк) +
(Число столбцов NULL + 7)/8
OPTIMIZE TABLE или
myisamchk -r.17.2.3.3. Сжатые табличные характеристики
BIGINT (восемь байтов)
может быть сохранен как столбец
TINYINT (один байт), если все его значения находятся в диапазоне
от -128 до 127.ENUM.DROP для удаления и
TRUNCATE TABLE, чтобы освободить таблицу.17.2.4. Проблемы таблиц MyISAM
17.2.4.1. Поврежденные таблицы
MyISAM
MyISAM очень надежен (все
изменения таблицы, сделанные запросом SQL, записаны перед его возвратом), Вы
можете все еще получить поврежденные таблицы, если какое-либо из следующих
событий имеет место:MyISAM.
Incorrect key file for table: '...'. Try to repair it
MyISAM, используя запрос
CHECK TABLE и провести ремонт
поврежденной таблицы MyISAM с
REPAIR TABLE. Когда
mysqld
не работает, Вы можете также проверить или восстановить таблицу с помощью
myisamchk.
См. разделы 14.7.2.2,
14.7.2.5 и
5.6.4.restarted mysqld
в журнале ошибок. Если есть такое сообщение, вероятно, что табличное
повреждение результат сбоя сервера. Иначе повреждение, возможно, произошло во
время нормального функционирования. Это ошибка. Вы должны попытаться создать
восстанавливаемый прецедент, который демонстрирует проблему. См. разделы
B.5.3.3 и
26.5.17.2.4.2. Проблемы от таблиц, не
закрываемых должным образом
MyISAM (.MYI)
имеет счетчик в заголовке, который может использоваться, чтобы проверить,
была ли таблица закрыта должным образом. Если Вы получаете следующее
предупреждение от CHECK TABLE
или myisamchk
, это означает, что этот счетчик вышел из синхронизации:
clients are using or haven't closed the table properly
Это предупреждение не обязательно означает, что таблица повреждена, но Вы
должны, по крайней мере, проверить таблицу.
FLUSH TABLES
была выполнена или потому что нет места в табличном кэше), счетчик
уменьшен, если таблица была обновлена в каком-либо пункте.MyISAM скопирована без применения
LOCK TABLES и
FLUSH TABLES.REPAIR TABLE или
CHECK TABLE на таблице, в то
время как это использовалось другим сервером. В этой установке безопасно
использовать CHECK TABLE,
хотя Вы могли бы получить предупреждение от других серверов. Однако,
REPAIR TABLE
применяться не должен потому, что когда один сервер заменяет файл с данными
новым, это неизвестно другим серверам.
17.3. Механизм хранения MEMORY
MEMORY (прежде известный как
HEAP) составляет таблицы специального назначения с содержанием,
которое сохранено в памяти. Поскольку данные уязвимы для катастрофических
отказов, проблемы аппаратных средств или отключения электричества, эти
таблицы используют в качестве временных рабочих областей или кэшей только для
чтения для данных, которые вытягивают из других таблиц.other tables.
MEMORY
Пределы хранения
RAM Транзакции
Нет Степень детализации блокировки
Таблица MVCC Нет
Картографические типы данных Нет
Индексирование геоданных
Нет Индексы B-tree
Да Индексы T-tree Нет
Индексы Hash Да Индексы Full-text search
Нет Кластеризуемые индексы
Нет Кэш данных N/A
Кэш индексов N/A
Сжатые данные Нет
Шифрование данных Да Поддержка базы данных кластера
Нет Репликация
Да Поддержка внешнего ключа
Нет Резервное копирование/восстановление
момента времени Да Кэш запросов
Да Статистика обновления для
словаря данных Да MEMORY для важных, высоконадежных или часто обновляемых
данных должны рассмотреть, является ли MySQL Cluster лучшим выбором. Типичный
случай использования для механизма MEMORY
имеет эти характеристики:MEMORY потеряны.MEMORY с более высокими исполнительными уровнями и обеспечивает
дополнительные функции, недоступные с MEMORY:BLOB и
TEXT), не поддержанные MEMORY
.MEMORY и MySQL Cluster см.
Scaling Web Services with MySQL Cluster: An Alternative to the
MySQL Memory Storage Engine. Этот отчет включает исследование качества
работы этих двух технологий и руководство, описывающее, как существующие
пользователи MEMORY могут мигрировать на MySQL Cluster.MEMORY не могут быть разделены.Технические характеристики
MEMORY ограничена утверждением, следующим из
выполнения единственного потока, и таблица блокируется, обрабатывая
обновления. Это ограничивает масштабируемость, когда загрузка увеличивается,
особенно для смесей запросов, которые включают запись.MEMORY,
они не обязательно быстрее InnoDB
на занятом сервере для запросов общего назначения или при рабочей нагрузке
чтения-записи. В частности таблица, заблокированная в связи с выполнением
обновлений, может замедлить параллельное использование таблиц
MEMORY из нескольких сеансов.MEMORY, Вы могли бы создать индексы как структуру данных хеша по
умолчанию (для того, чтобы искать единственные значения, основанные на
уникальном ключе) или структуру данных B-tree общего назначения
(для всех видов запросов, вовлекающих равенство, неравенство или операторы
диапазона, такие как "меньше чем" или "больше чем"). Следующие разделы
иллюстрируют синтаксис для того, чтобы создать оба вида индексов.Характеристики таблиц MEMORY
MEMORY не создает файлов на диске.
Табличное определение сохранено в словаре данных MySQL.MEMORY таблиц есть следующие характеристики:MEMORY выделено маленькими блоками.
Таблицы используют 100% динамическое хеширование для вставок. Никакая область
переполнения или дополнительное ключевое пространство не нужны. Никакое
дополнительное пространство не необходимо для свободных списков. Удаленные
строки помещены в связанный список и снова использованы, когда Вы вставляете
новые данные в таблицу. Таблицы MEMORYтакже не имеют ни одной из
проблем обычно связываемых с удалением плюс вставкой в хешированных таблицах.
MEMORY используют формат хранения строки
фиксированной длины. Типы переменной длины, например,
VARCHAR
сохранены, используя фиксированную длину.MEMORY не могут содержать столбцы
BLOB или
TEXT.MEMORY включает поддержку столбцов
AUTO_INCREMENT.TEMPORARY MEMORY совместно
использованы всеми клиентами, точно так же как любые другие
не-TEMPORARY таблицы.DDL-операции для таблиц MEMORY
MEMORY, определите пункт
ENGINE=MEMORY в
CREATE TABLE.
CREATE TABLE t (i INT) ENGINE = MEMORY;
Как обозначено именем механизма, таблицы MEMORY
сохранены в памяти. Они используют хеш-индексы по умолчанию, которые делают
их очень быстрыми для поисков единственного значения и очень полезными для
того, чтобы составить временные таблицы. Однако, когда сервер закрывается,
все строки, сохраненные в таблицах MEMORY, потеряны. Сами
таблицы продолжают существовать, потому что их определения сохранены в
словаре данных MySQL, но они пусты, когда сервер перезапускается.
MEMORY:
mysql> CREATE TABLE test ENGINE=MEMORY
-> SELECT ip, SUM(downloads) AS down
-> FROM log_table GROUP BY ip;
mysql> SELECT COUNT(ip),AVG(down) FROM test;
mysql> DROP TABLE test;
Максимальный размер таблиц MEMORY ограничен системной переменной
max_heap_table_size
, у которой есть значение по умолчанию 16 МБ. Провести в жизнь
различные пределы размера для таблиц MEMORY можно, изменив
значение этой переменной. Значение в действительности для
CREATE TABLE, последующего
ALTER TABLE или
TRUNCATE TABLE, это
значение, используемое для жизни таблицы. Перезапуск сервера также
устанавливает максимальный размер существующих таблиц MEMORY
к глобальной
max_heap_table_size. Вы можете установить размер для отдельных
таблиц как описано позже в этом разделе.
Индексы
MEMORY поддерживает оба индекса:
HASH и BTREE. Вы можете определить один или другой
для данного индекса, добавляя USING:
CREATE TABLE lookup (id INT, INDEX USING HASH (id)) ENGINE = MEMORY;
CREATE TABLE lookup (id INT, INDEX USING BTREE (id)) ENGINE = MEMORY;
MEMORY могут иметь до 64 индексов на таблицу, 16
столбцов на индексов и максимальную длину ключа 3072 байтов.BTREE, чтобы избежать этой проблемы.MEMORY могут быть групповые ключи.
Это необычная особенность выполнения хеш-индекса.NULL
.
Создаваемые пользователем и временные таблицы
MEMORY сохранено в памяти, которую
совместно используют с внутренними временными таблицами, которые сервер
составляет на лету, обрабатывая запросы. Однако, два типа таблиц отличаются:
таблицы MEMORY не подвергаются преобразованию хранения, тогда
как внутренние временные таблицы:MEMORY никогда не
преобразовываются в дисковые таблицы.Загрузка данных
MEMORY, когда сервер MySQL
запускается, Вы можете использовать опцию
--init-file.
Например, Вы можете поместить запросы
INSERT INTO ... SELECT или
LOAD DATA INFILE
в этот файл, чтобы загрузить таблицу из постоянного хранилища данных. См.
разделы 6.1.4 и
14.2.6.Таблицы MEMORY и репликация
MEMORY становятся пустыми, когда сервер закрыт и
перезапущен. Если сервер ведущее устройство, его ведомые устройства не знают,
что эти таблицы стали пустыми, таким образом, Вы видите устаревший контент,
если Вы выбираете данные из таблиц на ведомых устройствах. Синхронизировать
таблицы MEMORY ведущего и ведомого устройств, когда таблица
MEMORY используется на ведущем устройстве, можно, добавив в
двоичный журнал ведущего устройства запрос
DELETE, чтобы освободить таблицу на ведомых устройствах также.
У ведомого устройства все еще есть устаревшие данные в таблице во время
интервала между перезапуском ведущего устройства и его первым использованием
таблицы. Чтобы избежать этого интервала, когда прямой запрос к ведомому
устройству мог возвратить устаревшие данные, используйте опцию
--init-file,
чтобы заполнить таблицу MEMORY на ведущем
устройстве при запуске.Управление использованием памяти
MEMORY, которые используются в то же самое время.DELETE или
TRUNCATE TABLE, чтобы
удалить все строки или удалить таблицу в целом, используя
DROP TABLE. Чтобы освободить
память, используемую удаленными строками, надо использовать
ALTER TABLE ENGINE=MEMORY.MEMORY,
вычислена, используя следующее выражение:
SUM_OVER_ALL_BTREE_KEYS(
max_length_of_key +
sizeof(char*) * 4) +
SUM_OVER_ALL_HASH_KEYS(sizeof(char*) * 2) +
ALIGN(length_of_row + 1, sizeof(char*))
ALIGN() представляет фактор округления, чтобы заставить длину
строки быть точно кратной размеру указателя char
sizeof(char*) = 4 на 32-bit системах и 8 на 64-bit машинах.
max_heap_table_size
устанавливает предел для максимального размера таблиц
MEMORY. Чтобы управлять максимальным размером для отдельных
таблиц, установите сеансовое значение этой переменной прежде, чем составить
каждую таблицу. Не изменяйте глобальное значение
max_heap_table_size
, если Вы не предназначаете значение, которое будет использоваться
для таблиц MEMORY, составленных всеми клиентами. Следующий
пример создает две таблицы MEMORY
с максимальным размером 1 МБ и 2 МБ, соответственно:
mysql> SET max_heap_table_size = 1024*1024;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE TABLE t1 (id INT, UNIQUE(id)) ENGINE = MEMORY;
Query OK, 0 rows affected (0.01 sec)
mysql> SET max_heap_table_size = 1024*1024*2;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE TABLE t2 (id INT, UNIQUE(id)) ENGINE = MEMORY;
Query OK, 0 rows affected (0.00 sec)
Обе таблицы возвращаются к глобальному значению
max_heap_table_size
, если сервер перезапускается.
MAX_ROWS в
CREATE TABLE для таблиц
MEMORY, чтобы обеспечить подсказку о числе строк, которое Вы
планируете сохранить в них. Это не позволяет таблице вырасти вне
max_heap_table_size
, которое все еще действует как ограничение на максимальный
табличный размер. Для максимальной гибкости в возможности использования
MAX_ROWS, установите
max_heap_table_size
по крайней мере, столь же высоко как значение, к которому Вы
хотите вырастить каждую таблицу MEMORY.Дополнительные ресурсы
MEMORY,
доступен на
http://forums.mysql.com/list.php?92.17.4. Механизм хранения CSV
CSV хранит данные в текстовых файлах,
используя отделенный запятыми формат значений.CSV всегда собирается в сервер MySQL.CSV, см. каталог
storage/csv дистрибутива исходных текстов MySQL.CSV, сервер создает файл с данными.
Имя файла с данными начинается с имени таблицы и имеет расширение
.CSV. Файл с данными это файл простого текста. Когда Вы
сохраняете данные в таблицу, механизм хранения сохраняет это в файл с данными
в отделенном запятыми формате значений.
mysql> CREATE TABLE test (i INT NOT NULL, c CHAR(10) NOT NULL)
-> ENGINE = CSV;
Query OK, 0 rows affected (0.12 sec)
mysql> INSERT INTO test VALUES(1,'record one'),(2,'record two');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM test;
+---+------------+
| i | c |
+---+------------+
| 1 | record one |
| 2 | record two |
+---+------------+
2 rows in set (0.00 sec)
Составление таблицы CSV также создает соответствующий метафайл, который
хранит статус таблицы и число строк, которые существуют в таблице. Название
этого файла то же самое, как название таблицы с расширением CSM.
test.CSV в каталоге базы данных,
создаваемый, выполняя предыдущие запросы, его содержание должно быть
похожим на это:
"1","record one"
"2","record two"
Этот формат может быть считан и даже записан приложениями для обработки
электронных таблиц, такими как Microsoft Excel или StarOffice Calc.
17.4.1. Восстановление и проверка
таблиц CSV
CHECK и
REPAIR, чтобы проверить и если возможно отремонтировать
поврежденную таблицу CSV.CHECK проверяет файл CSV на законность, ища правильные
полевые разделители, экранированные области, правильное число областей по
сравнению с табличным определением и существование соответствующего
метафайла. Первая недопустимая обнаруженная строка сообщит об ошибке.
Проверка допустимой таблицы производит вывод как показано ниже:
mysql> check table csvtest;
+--------------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------+
| test.csvtest | check | status | OK |
+--------------+-------+----------+----------+
1 row in set (0.00 sec)
Проверка на поврежденной таблице возвращает ошибку:
mysql> check table csvtest;
+--------------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------+
| test.csvtest | check | error | Corrupt |
+--------------+-------+----------+----------+
1 row in set (0.01 sec)
Если проверка терпит неудачу, таблица отмечена как разрушенная.
Как только таблица была отмечена как поврежденная, она автоматически
восстановлена, когда Вы в следующий раз запустите CHECK или
выполните SELECT.
Соответствующее поврежденное состояние и новое состояние будут выведены на
экран из CHECK:
mysql> check table csvtest;
+--------------+-------+----------+----------------------------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------------------------+
| test.csvtest | check | warning | Table is marked as crashed |
| test.csvtest | check | status | OK |
+--------------+-------+----------+----------------------------+
2 rows in set (0.08 sec)
Чтобы восстановить таблицу, Вы можете использовать REPAIR,
это копирует так много допустимых строк существующих данных CSV, насколько
возможно, а затем заменяет существующий файл CSV восстановленными строками.
Любые строки вне поврежденных данных потеряны.
mysql> repair table csvtest;
+--------------+--------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------------+--------+----------+----------+
| test.csvtest | repair | status | OK |
+--------------+--------+----------+----------+
1 row in set (0.02 sec)
17.4.2. Ограничения CSV
CSV не поддерживает индексацию.CSV не поддерживает разделение.CSV должны иметь признак NOT NULL на всех столбцах.
Однако, для обратной совместимости, Вы можете продолжить использовать таблицы
со столбцами, допускающими null, которые создавались в предыдущих выпусках
MySQL (Bug #32050).17.5. Механизм хранения ARCHIVE
ARCHIVE производит таблицы специального
назначения, которые хранят большое количество неиндексированных данных в
очень маленьком виде.ARCHIVE
Пределы хранения
Нет Транзакции Нет
Степень детализации блокировки
Строка MVCC Нет
Картографические типы данных Да
Индексирование геоданных
Нет Индексы B-tree
Нет Индексы T-tree Нет
Индексы Hash Нет Индексы Full-text search
Нет Кластеризуемые индексы
Нет Кэш данных
Нет Кэш индексов
Нет Сжатые данные Да
Шифрование данных Да Поддержка базы данных кластера
Нет Репликация
Да Поддержка внешнего ключа
Нет Резервное копирование/восстановление
момента времени Да Кэш запросов
Да Статистика обновления для
словаря данных Да ARCHIVE включен в двоичные дистрибутивы
MySQL. Чтобы включить этот механизму хранения, если Вы создаете MySQL из
исходных текстов, вызовите CMake с опцией
-DWITH_ARCHIVE_STORAGE_ENGINE.ARCHIVE находятся
в каталоге storage/archive исходных текстов MySQL.ARCHIVE, механизм хранения создает
файлы с именами, которые начинаются с имени таблицы. У файла с данными есть
расширение .ARZ. Файл .ARN может появиться во время
операций оптимизации. Вы можете проверить, доступен ли механизм хранения
ARCHIVE с помощью запроса
SHOW ENGINES.ARCHIVE поддерживает
INSERT,
REPLACE и
SELECT, но не
DELETE или
UPDATE. Это действительно
поддерживает ORDER BY, столбцы
BLOB. Механизм ARCHIVE использует блокировку
на уровне строки.ARCHIVE поддерживает признак столбца
AUTO_INCREMENT. У столбца AUTO_INCREMENT может быть
уникальный или групповой индекс. Попытка создать индексирование на любом
другом столбце приводит к ошибке. Механизм ARCHIVE также
поддерживает табличную опцию AUTO_INCREMENT в
CREATE TABLE, чтобы
определить начальное значение последовательности для новой таблицы.ARCHIVE не поддерживает вставку значения в столбец
AUTO_INCREMENT меньше, чем текущее максимальное значение
столбца. Попытки сделать так приводят к ошибке
ER_DUP_KEY.ARCHIVE игнорирует столбцы
BLOB, если их не требуют.ARCHIVE не поддерживает разделение.ARCHIVE использует zlib сжатие данных без потерь
(см. http://www.zlib.net/).
Вы можете использовать OPTIMIZE TABLE
, чтобы проанализировать таблицу и упаковать ее в меньший формат
(о причинах использования OPTIMIZE
TABLE см. позже в этом разделе). Механизм также поддерживает
CHECK TABLE.
Есть несколько типов вставок, которые используются:INSERT
только продвигает строки в буфер сжатия. Вставка в буфер защищена
блокировкой. SELECT
сбрасывает буфер явно.SELECT
никогда не вызывает сброс оптовой вставки, если нормальная вставка не
происходит, в то время как она загружается.
SELECT выполняет полное сканирование таблицы: когда
SELECT происходит, это узнает,
сколько строк в настоящее время доступно и читает это число строк.
SELECT выполнен как
последовательное чтение. Отметьте, что многие запросы
SELECT во время вставки могут
ухудшить сжатие, если только не используются оптовые вставки. Чтобы
достигнуть лучшего сжатия, Вы можете использовать
OPTIMIZE TABLE или
REPAIR TABLE. Число строк в
таблицах ARCHIVE, о которых сообщает
SHOW TABLE STATUS,
всегда точно. См. разделы 14.7.2.4,
14.7.2.5 и
14.7.5.36.Дополнительные ресурсы
ARCHIVE,
доступен на
http://forums.mysql.com/list.php?112.17.6. Механизм хранения BLACKHOLE
BLACKHOLE действует как
дыра памяти, который принимает данные, но не хранит
их. Извлечения всегда возвращают пустой результат:
mysql> CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO test VALUES(1,'record one'),(2,'record two');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM test;
Empty set (0.00 sec)
Чтобы включить механизм хранения BLACKHOLE, если Вы создаете
MySQL из исходных текстов, вызовите CMake с
опцией
-DWITH_BLACKHOLE_STORAGE_ENGINE.
BLACKHOLE находится в каталоге
sql исходных текстов MySQL.BLACKHOLE, сервер создает табличное
определение в глобальном словаре данных.
Нет никаких файлов, связанных с таблицей.BLACKHOLE поддерживает все виды индексов.
Таким образом, Вы можете включать индексные
декларации в табличном определении.BLACKHOLE не поддерживает разделение.BLACKHOLE
с помощью SHOW ENGINES.BLACKHOLE не хранят данных, но если
двоичное журналирование, основанное на запросе, включено, запросы SQL
зарегистрированы и копируются к ведомым серверам. Это может быть полезно как
повторитель или фильтр.BLACKHOLE примерно так: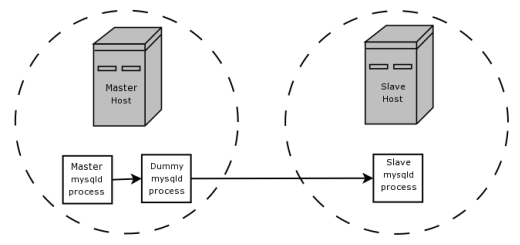
replicate-do-* и
replicate-ignore-*, и пишет отфильтрованный результат
в собственный двоичный журнал. См.
раздел 19.1.6. Этот фильтруемый журнал обеспечен ведомому устройству.INSERT для таблиц
BLACKHOLE работают как ожидалось. Однако, потому что
BLACKHOLE фактически не хранит данных, триггеры
UPDATE и
DELETE не активированы: предложение
FOR EACH ROW в определении не применяется, потому что
нет никаких строк.BLACKHOLE включают:BLACKHOLE с и без журналирования.BLACKHOLE по существу пустой механизм хранения, таким
образом, это может использоваться для того, чтобы учесть исполнительные узкие
места, не связанные с механизмом хранения непосредственно.BLACKHOLE осведомлен о транзакции, в том смысле, что
переданные транзакции записаны в двоичный журнал, а отмененные нет.INSERT непосредственно или
посредством использования SET INSERT_ID.INSERT_ID
в контексте всегда будет то же самое. Репликация поэтому потерпит неудачу
из-за попытки вставки строки с двойным значением столбца первичного ключа.binlog_format=ROW
), ведомое устройство, где последние столбцы отсутствуют в таблице,
поддержано, как описано в
разделе 19.4.1.10
.BLACKHOLE. Это выполнено подобном тому, как основная табличная
фильтрация достигнута: при использовании BLACKHOLE и опций
--replicate-do-table или
--replicate-ignore-table.
CREATE TABLE t1 (public_col_1, ..., public_col_N,
secret_col_1, ..., secret_col_M) ENGINE=MyISAM;
Установка для ведомого устройства, которому доверяют:
CREATE TABLE t1 (public_col_1, ..., public_col_N) ENGINE=BLACKHOLE;
Установка для ведомого устройства, которому не доверяют:
CREATE TABLE t1 (public_col_1, ..., public_col_N) ENGINE=MyISAM;
17.7. Механизм хранения MERGE
MERGE, также известный как
MRG_MyISAM, это набор идентичных таблиц MyISAM,
которые могут использоваться в качестве одной. "Идентичные"
означает, что все таблицы имеют идентичные столбцы и индексную
информацию. Вы не можете слить таблицы MyISAM, в которых столбцы
перечислены в различном порядке, не имеют точно тех же самых столбцов или
имеют индексы в различном порядке. Однако, любая из таблиц MyISAM
может быть сжата с
myisampack. См. раздел
5.6.6. Различия в таких табличных опциях, как AVG_ROW_LENGTH
, MAX_ROWS или PACK_KEYS не имеют значения.
MERGE это разделенная таблица, которая
хранит разделение единственной таблицы в отдельных файлах и позволяет
некоторым операциям быть выполненными более эффективно. Для получения
дополнительной информации см. главу 20.MERGE, MySQL создает файл
.MRG на диске, который содержит названия основных таблиц
MyISAM, которые должны использоваться в качестве одной. Формат
таблицы MERGE сохранен в словаре данных MySQL. Основные таблицы
не должны быть в той же самой базе данных, что и MERGE.SELECT,
DELETE,
UPDATE и
INSERT на таблицах
MERGE. Вы должны иметь привилегии
SELECT,
DELETE и
UPDATE на таблицах
MyISAM, которые Вы отображаете на таблицу MERGE.
MERGE влечет за собой следующий вопрос
безопасности: если у пользователя есть доступ к MyISAM-таблице
t, этот пользователь может создать
MERGE-таблицу m, которая получает доступ
к t. Однако, если привилегии пользователя на
t впоследствии отменяются, пользователь может
продолжить получать доступ к t через
m.DROP TABLE с
таблицей MERGE удалит только спецификацию MERGE.
Основные таблицы не затронуты.MERGE, Вы должны определить опцию
UNION=(, которая указывает,
которые таблицы list-of-tables)MyISAM использовать. Вы можете произвольно
определить опцию INSERT_METHOD, чтобы управлять, как вставлять в
таблицу MERGE. Используйте значение FIRST или
LAST, чтобы вставки юыли сделаны в первой или последней основной
таблице, соответственно. Если Вы не определяете INSERT_METHOD
или если Вы определяете это со значением NO, вставка в таблицу
MERGE не разрешена, и попытка ее сделать вернет ошибку.MERGE:
mysql> CREATE TABLE t1 (a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> message CHAR(20)) ENGINE=MyISAM;
mysql> CREATE TABLE t2 (a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> message CHAR(20)) ENGINE=MyISAM;
mysql> INSERT INTO t1 (message) VALUES ('Testing'),('table'),('t1');
mysql> INSERT INTO t2 (message) VALUES ('Testing'),('table'),('t2');
mysql> CREATE TABLE total (a INT NOT NULL AUTO_INCREMENT,
-> message CHAR(20), INDEX(a))
-> ENGINE=MERGE UNION=(t1,t2) INSERT_METHOD=LAST;
Столбец a индексирован как PRIMARY KEY в основной
таблице MyISAM, но не в таблице MERGE.
Там это индексировано, но не как PRIMARY KEY, так как таблица
MERGE не может провести в жизнь уникальность по набору основных
таблиц. Точно так же столбец с индексом UNIQUE в основных
таблицах, должен быть индексирован в MERGE, но
не как UNIQUE.
MERGE Вы можете использовать ее, чтобы
создать запросы, которые воздействуют на группу таблиц в целом:
mysql> SELECT * FROM total;
+---+---------+
| a | message |
+---+---------+
| 1 | Testing |
| 2 | table |
| 3 | t1 |
| 1 | Testing |
| 2 | table |
| 3 | t2 |
+---+---------+
Чтобы переопределить таблицу MERGE к иному набору таблиц
MyISAM, Вы можете использовать один из следующих методов:
DROP таблицу MERGE и пересоздайте ее.
ALTER TABLE , чтобы изменить список основных таблиц.
tbl_name
UNION=(...)ALTER TABLE ... UNION=()
(то есть, с пустым предложением UNION
), чтобы удалить все основные таблицы. Однако, в этом случае, таблица
эффективно пуста и вставки терпят неудачу, потому что нет никакой основной
таблицы, чтобы взять новые строки. Такая таблица могла бы быть полезной как
шаблон для создания новой таблицы MERGE с помощью
CREATE TABLE ... LIKE.
MERGE. Соответствие проверено, когда таблица,
которая является частью MERGE, открыта, а не когда
MERGE-таблица составлена. Если какая-либо таблица не проходит
проверку соответствия, работа, которая вызвала открытие таблицы, терпит
неудачу. Это означает, что изменения определений таблиц в пределах
MERGE может вызвать отказ при доступе к MERGE.
Проверка соответствия относится к каждой таблице:MERGE должен соответствовать.MERGE и основных таблицах сравнены и должны
удовлетворить этим проверкам:
MERGE
должен быть равным.MERGE должна быть равной.
MERGE может быть
NULL.MERGE. Основная таблица может иметь больше индексов, чем
MERGE, но не может иметь меньше.MERGE и
MyISAM. См. Bug #33653.MERGE
должен быть тем же самым.MERGE должно быть тем же самым.NULL.
MERGE не может быть открыта или использоваться
из-за проблемы с основной таблицей, CHECK
TABLE покажет информацию о том, которая таблица вызвала проблему.
Дополнительные ресурсы
MERGE,
доступен на
http://forums.mysql.com/list.php?93.17.7.1.
Табличные преимущества и недостатки MERGE
MERGE могут помочь Вам решить следующие проблемы:MERGE,
чтобы использовать их в качестве одной.MERGE структурировала этот
путь, что может быть намного быстрее, чем использование
единственной большой таблицы.MERGE для других. У Вас даже может быть много
отличающихся MERGE, которые используют
накладывающиеся наборы таблиц.MERGE,
чем восстановить единственную большую таблицу.MERGE
не должна поддерживать собственное индексирование, потому что она использует
индексирование отдельных таблиц. В результате MERGE
очень быстры, чтобы создать или повторно отобразить.
Вы должны все еще определить индекс, когда Вы создаете
MERGE, даже при том, что индексы не создаются.MERGE. Это намного
быстрее и сохраняет много дискового пространства.MyISAM связана этим пределом, но не
набор таблиц MyISAM.MyISAM, определяя MERGE, которая отображается на
эту единственную таблицу. Не должно быть никакого действительно известного
исполнительного воздействия от выполнения этого (только несколько косвенных
требований и вызовов memcpy() к каждому чтению).MERGE-таблицы:MyISAM-таблицы для MERGE.MyISAM недоступны в MERGE.
Например, Вы не можете создать FULLTEXT индекс на
MERGE. Вы можете создать индекс FULLTEXT на
основных таблицах MyISAM, но Вы не можете искать в
MERGE по нему.MERGE-таблица является невременной, все основные
MyISAM-таблицы должны быть невременными. Если MERGE
является временной, MyISAM-таблицы могут быть любым
соединением временных и невременных.MERGE используют больше описателей файла, чем
MyISAM. Если 10 клиентов используют таблицу MERGE,
которая отображается на 10 таблиц, сервер использует (10 * 10) + 10
описателей файла. (10 описателей файла с данными для каждого из этих 10
клиентов, и 10 описателей индексного файла совместно использованы
среди всех клиентов.MERGE должен запустить чтение на всех основных таблицах, чтобы
проверить, какой наиболее близко соответствует. Чтобы считать следующее
индексное значение, MERGE должен искать буферы чтения, чтобы
найти следующее значение. Только когда каждый индексный буфер израсходован,
механизм хранения должен читать следующий индексный блок. Это делает
индексы MERGE намного медленнее на запросах
eq_ref,
но не намного медленнее на поисках
ref.17.7.2. Табличные проблемы MERGE
MERGE:MERGE с невременными таблицами MyISAM.ALTER TABLE
, чтобы изменить MERGE к другому механизму хранения,
отображение на основные таблицы потеряно. Вместо этого строки основных
таблиц MyISAM скопированы в измененную таблицу, которая
использует указанный механизм хранения.INSERT_METHOD для MERGE
показывает, какую из основных таблиц MyISAM
использовать для вставок в MERGE. Однако, использование опции
AUTO_INCREMENT для этой таблицы MyISAM не имеет
никакого эффекта для вставок в MERGE, пока по крайней мере одна
строка не была вставлена непосредственно в MyISAM.MERGE не может поддержать ограничения уникальности
по всей таблице. Когда Вы выполняете
INSERT, данные входят в первую или
последнюю таблицу MyISAM table (как определено
INSERT_METHOD). MySQL гарантирует, что уникальные значения ключа
остаются уникальными в пределах этой таблицы MyISAM,
но не по всем основным таблицам в наборе.MERGE не может провести в жизнь
уникальность по набору основных таблиц,
REPLACE
не работает как ожидалось. Два ключевых факта:
REPLACE
может обнаружить уникальные ключевые нарушения только в основной таблице, в
которую собирается записать (которая определена INSERT_METHOD).
Это отличается от нарушений в таблице MERGE непосредственно.
REPLACE обнаруживает
уникальное ключевое нарушение, это изменит только соответствующую строку в
основной таблице, которую пишет, то есть, первую или последнюю таблицу, как
определено INSERT_METHOD.INSERT
... ON DUPLICATE KEY UPDATE.MERGE не поддерживают разделение. Таким образом, Вы не
можете разделить MERGE или любую из основных таблиц.ANALYZE
TABLE, REPAIR TABLE
, OPTIMIZE TABLE,
ALTER TABLE,
DROP TABLE,
DELETE без предложения
WHERE или TRUNCATE TABLE
на любой из таблиц, которые отображены в открытую таблицу
MERGE. Если Вы делаете так, MERGE может все еще
обратиться к оригинальной таблице и привести к неожиданным результатам. Чтобы
обойти эту проблему, гарантируйте, что нет открытых таблиц MERGE
с помощью FLUSH TABLES
до выполнения любой из названных операций.
MERGE сообщит о табличном повреждении. Если это происходит после
одной из названных операций на основной MyISAM-таблице,
сообщение повреждения является поддельным. Выполните запрос
FLUSH TABLES
после изменения MyISAM.DROP TABLEна таблице,
которая используется MERGE не работает в Windows потому, что
табличное отображение механизма хранения MERGE скрыто от
верхнего уровня MySQL. Windows не разрешает открытым файлам быть удаленными,
таким образом, Вы сначала должны сбросить все таблицы MERGE (с
FLUSH TABLES) или удалить
MERGE прежде, чем удалить основную таблицу.MyISAM таблицы и MERGE
проверено, когда к таблицам получают доступ (например, как часть
SELECT или
INSERT). Проверки гарантируют что
определения таблиц соответствуют определению, сравнивая порядок следования
столбцов, типы, размеры и связанные индексы. Если есть различие между
таблицами, ошибка возвращена, и запрос терпит неудачу. Поскольку эти проверки
имеют место, когда таблицы открыты, любые изменения определения единственной
таблицы, включая изменения столбца, упорядочивания столбцов и изменения
механизма хранения заставят запрос терпеть неудачу.MERGE и основных таблицах
должен быть тем же самым. Если Вы используете
ALTER TABLE, чтобы добавить
индекс UNIQUE к таблице, используемой в MERGE,
и затем используете ALTER TABLE,
чтобы добавить групповой индекс на MERGE, порядок индексов
отличается для таблиц, если уже был групповой индекс в основной таблице. Это
происходит потому, что ALTER TABLE
помещает индексы UNIQUE перед групповыми, чтобы облегчить
быстрое обнаружение дубликатов ключей. Следовательно, запросы на таблицах с
таким индексом могут возвратить неожиданные результаты.tbl_name.MRG' (errno: 2)
, это вообще указывает, что некоторые из основных таблиц не используют
механизм хранения MyISAM. Подтвердите, что все
эти таблицы MyISAM.MERGE 264
(~1.844E+19: то же самое касается MyISAM). Невозможно слить
много таблиц MyISAM в одну MERGE, у которой было бы
больше, чем это число строк.MyISAM, отличающихся форматом
строк, как в настоящее время известно, терпит неудачу. См. Bug #32364.MERGE, когда активна LOCK
TABLES. Следующее НЕ работает:
CREATE TABLE m1 ... ENGINE=MRG_MYISAM ...;
LOCK TABLES t1 WRITE, t2 WRITE, m1 WRITE;
ALTER TABLE m1 ... UNION=(t1,t2) ...;
Однако, Вы можете сделать это с временной таблицей MERGE.MERGE с
CREATE ... SELECT как временную таблицу
MERGE или невременную MERGE. Например:
CREATE TABLE m1 ... ENGINE=MRG_MYISAM ... SELECT ...;
Попытки сделать это приведут к ошибке:
tbl_name is not BASE TABLE.PACK_KEYS
вызывает неожиданные результаты, если основные таблицы содержат столбцы
CHAR или BINARY. Как обходное решение, можно
использовать ALTER TABLE, чтобы гарантировать, что у всех
вовлеченных таблиц есть то же самое значение PACK_KEYS (Bug
#50646).17.8.
Механизм хранения FEDERATED
FEDERATED позволяет Вам доступ к данным
от удаленной базы данных MySQL, не используя технологию кластера или
репликации. Запросы к локальной таблице FEDERATED автоматически
вытягивают данные из удаленных (объединенных) таблиц. Никакие данные не
хранятся в местных таблицах.FEDERATED, если Вы создаете
MySQL из исходных текстов, вызовите CMake с
опцией
-DWITH_FEDERATED_STORAGE_ENGINE.FEDERATED не включен по умолчанию в рабочем
сервере, чтобы его включить, Вы должны запустить сервер
MySQL с опцией --federated.FEDERATED находится в каталоге
storage/federated исходных текстов MySQL.17.8.1. Краткий обзор механизма
хранения FEDERATED
MyISAM, CSV или InnoDB),
таблица состоит из табличного определения и связанных данных. Когда Вы
создаете таблицу FEDERATED, табличное определение то же самое,
но физическое хранение данных обработано на удаленном сервере.FEDERATED состоит из двух элементов:mysqld,
включая MyISAM или InnoDB.FEDERATED на локальном сервере,
операции, которые обычно вставляли бы, обновляли или удаляли информацию из
местного файла с данными вместо этого посланы в удаленный сервер для
выполнения, где они обновляют файл с данными на удаленном сервере.FEDERATED показана на
рис. 17.1.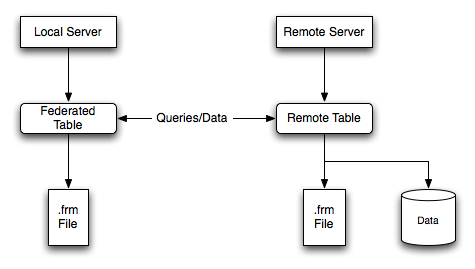
FEDERATED, потоки информации между локальным сервером (где
запрос SQL выполнен) и удаленным сервером (где данные
физически хранятся) следующие:FEDERATED и создает соответствующий запрос SQL, который
относится к отдаленной таблице.mysql_real_query()
, чтобы послать запрос. Чтобы считать набор результатов, это
использует
mysql_store_result() и передает строки по одной, используя
mysql_fetch_row().17.8.2. Как составить таблицу FEDERATED
FEDERATED,
Вы должны следовать за этими шагами:SHOW CREATE TABLE.
CREATE TABLE test_table (id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id), INDEX name (name),
INDEX other_key (other)) ENGINE=MyISAM
DEFAULT CHARSET=latin1;
Чтобы составить местную таблицу, которая будет объединенной с
отдаленной таблицей, есть две доступные опции. Вы можете или составить
местную таблицу и определить строку подключения (содержащую имя сервера, вход
в систему и пароль), чтобы соединиться с отдаленной таблицей, используя
CONNECTION, или Вы можете использовать существующее соединение,
которое Вы ранее создали с использованием
CREATE SERVER.
FEDERATED добавлением
индекса к таблице на узле. Оптимизация произойдет, потому что запрос,
посланный в удаленный сервер, будет включать содержание предложения
WHERE, посланного в удаленный сервер, и впоследствии выполнен в
местном масштабе. Это уменьшает сетевой трафик, который иначе запросил бы всю
таблицу от сервера для местной обработки.17.8.2.1. Создание таблицы
FEDERATED, используя CONNECTION
CONNECTION после типа механизма в
CREATE TABLE. Например:
CREATE TABLE federated_table (id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id), INDEX name (name),
INDEX other_key (other)) ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='mysql://fed_user@remote_host:9306/federated/test_table';
CONNECTION заменяет COMMENT, используемый в
некоторых предыдущих версиях MySQL.CONNECTION содержит информацию, запрошенную, чтобы
соединиться с удаленным сервером, содержащим таблицу, которая будет
использоваться, чтобы физически хранить данные. Строка подключения определяет
имя сервера, параметры входа в систему, номер порта и информацию о базе
данных/таблице. В примере отдаленная таблица находится на сервере
remote_host, порт 9306. Имя и номер порта должны соответствовать
имени хоста (или IP-адресу) и номеру порта отдаленного сервера MySQL, который
Вы хотите использовать в качестве Вашей отдаленной таблицы.
Здесь:
scheme://user_name[:password]@
host_name[:port_num]/db_name/tbl_name
scheme: Признанный протокол соединения.
Только mysql поддержан как scheme.user_name: Имя пользователя для соединения. Это
пользователь, который должен быть создан на удаленном сервере, и должен иметь
подходящие привилегии, чтобы выполнить необходимые действия.
(SELECT,
INSERT,
UPDATE и т.д.)
на отдаленной таблице.password: (дополнительно) соответствующий пароль
для user_name.host_name: Имя хоста или
IP-адрес удаленного сервера.port_num: (дополнительно) номер порта для
удаленного сервера. Значение по умолчанию 3306.db_name: Название базы данных,
содержащей отдаленную таблицу.tbl_name: Название отдаленной таблицы. Имя местной
и отдаленной таблиц не должны совпадать.
CONNECTION='mysql://username:password@hostname:port/database/tablename'
CONNECTION='mysql://username@hostname/database/tablename'
CONNECTION='mysql://username:password@hostname/database/tablename'
17.8.2.2. Создание таблицы
FEDERATED, используя CREATE SERVER
FEDERATED на том же самом
сервере, или если Вы хотите упростить процесс создания таблиц
FEDERATED, Вы можете использовать
CREATE SERVER, чтобы
определить параметры соединения сервера, как Вы задали
бы строку CONNECTION.CREATE SERVER:
CREATE SERVER
server_name
FOREIGN DATA WRAPPER wrapper_name
OPTIONS (option [, option] ...)
server_name используется в строке подключения, создавая
новую таблицу FEDERATED.
CONNECTION:
CONNECTION='mysql://fed_user@remote_host:9306/federated/test_table';
Вы использовали бы следующий запрос:
CREATE SERVER fedlink FOREIGN DATA WRAPPER mysql
OPTIONS (USER 'fed_user', HOST 'remote_host', PORT 9306,
DATABASE 'federated');
Чтобы создать таблицу FEDERATED, которая использует это
соединение, Вы все еще используете ключевое слово CONNECTION, но
определяете имя, которое Вы использовали в
CREATE SERVER.
CREATE TABLE test_table (id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id), INDEX name (name),
INDEX other_key (other)) ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='fedlink/test_table';
Имя соединения в этом примере содержит название соединения
(fedlink) и название таблицы (test_table),
отделенное наклонной чертой. Если Вы определяете только имя соединения без
имени таблицы, имя местной таблицы используется вместо этого.
CREATE SERVER
принимает те же самые параметры, как строка CONNECTION.
CREATE SERVER обновляет
строки в таблице mysql.servers. См. следующую таблицу для
информации о связи между параметрами в строке подключения, опциями в
CREATE SERVER и
и столбцами в таблице mysql.servers. Для ссылки формат строки
CONNECTION следующий:
scheme://user_name[:password]@
host_name[:port_num]/db_name/tbl_name
Описание Строка
CONNECTIONОпция
CREATE SERVERСтолбец mysql.serversСхема соединения scheme
wrapper_nameWrapperОтдаленный пользователь user_name
USERUsernameОтдаленный пароль password
PASSWORDPasswordОтдаленный узел host_name
HOSTHostОтдаленный порт port_num
PORTPortОтдаленная база данных db_name
DATABASEDb17.8.3. Примечания и подсказки о
механизме хранения FEDERATED
FEDERATED:FEDERATED могут копироваться к другим ведомым
устройствам, но Вы должны гарантировать, что ведомые серверы в состоянии
использовать комбинацию пользователя/пароля, которая определена в строке
CONNECTION (или строке в таблице mysql.servers),
чтобы соединиться с удаленным сервером.FEDERATED:FEDERATED,
должна существовать прежде, чем Вы попытаетесь получить
доступ к таблице через FEDERATED.FEDERATED
указать на другую, но Вы должны бояться создать петлю.FEDERATED не поддерживает индексы в обычном смысле,
потому как доступ к табличным данным обработан отдаленно, это фактически
отдаленная таблица, которая использует индексы. Это означает, что для
запроса, который не может использовать любой индекс и требует полного
сканирования таблицы, сервер приносит все строки от отдаленной таблицы и
фильтрует их в местном масштабе. Это происходит независимо от любых
WHERE или LIMIT, используемых с этим
SELECT:
эти пункты применены в местном масштабе к возвращенным строкам.
FEDERATED. Например, создание таблицы FEDERATED
с индексной приставкой на столбцах VARCHAR
, TEXT или
BLOB потерпит неудачу. Следующее
определение в MyISAM допустимо:
CREATE TABLE `T1`(`A` VARCHAR(100),UNIQUE KEY(`A`(30))) ENGINE=MYISAM;
Ключевая приставка в этом примере является несовместимой с
FEDERATED, а эквивалентный запрос потерпит неудачу:
CREATE TABLE `T1`(`A` VARCHAR(100),UNIQUE KEY(`A`(30))) ENGINE=FEDERATED
CONNECTION='MYSQL://127.0.0.1:3306/TEST/T1';
Если возможно, Вы должны попытаться отделить столбец и индексировать
определение, составляя таблицы на удаленном сервере и на локальном сервере,
чтобы избежать, чтобы они индексировали проблемы.SELECT,
INSERT,
UPDATE и
DELETE, но не
HANDLER.FEDERATED понимает
SELECT,
INSERT,
UPDATE,
DELETE,
TRUNCATE TABLE и индексы.
Это не поддерживает ALTER TABLE
или любые запросы языка определения данных, которые непосредственно
затрагивают структуру таблицы, кроме DROP
TABLE. Текущее выполнение не использует подготовленные запросы.
FEDERATED принимает
INSERT ... ON DUPLICATE KEY UPDATE, но если происходит
ошибка дубликата ключа, запрос терпит неудачу с ошибкой.FEDERATED, выполняя большую вставку (например, на
INSERT INTO ... SELECT ...)
медленнее чем с другими табличными типами, потому что каждая выбранная строка
обработана как отдельный запрос INSERT
на таблице FEDERATED.FEDERATED выполняет обработку больших вставок
таким образом, что много строк посылаются в отдаленную таблицу в пакете.
Это обеспечивает исполнительное усовершенствование и позволяет отдаленной
таблице выполнить усовершенствование. Кроме того, если отдаленная таблица
является транзакционной, она позволяет отдаленному механизму хранения
выполнить отмену транзакции должным образом в случае ошибки. У этой
способности есть следующие ограничения:
INSERT ... ON
DUPLICATE KEY UPDATE.FEDERATED узнать,
изменилась ли отдаленная таблица. Причина этого состоит в том, что эта
таблица должна работать как файл с данными, который никогда не писался бы
ничем кроме системы базы данных. Целостность данных в местной таблице могла
быть нарушена, если бы было какое-либо изменение отдаленной базы данных.CONNECTION, Вы не можете использовать символ '@'
в пароле. Вы можете обойти это ограничение при использовании
CREATE SERVER,
чтобы создать соединение.insert_id и
timestamp
не размножены к источнику данных.DROP TABLE для
FEDERATED удаляет только местную таблицу, но не отдаленную.FEDERATED не работают с кэшем запроса.FEDERATED.17.8.4.
Ресурсы механизма хранения FEDERATED
FEDERATED:FEDERATED
доступен на
http://forums.mysql.com/list.php?105.17.9. Механизм хранения EXAMPLE
EXAMPLE это механизм, который ничего не
делает. Его цель состоит в том, чтобы служить примером в исходном коде MySQL,
который иллюстрирует, как начать писать новые механизмы хранения. Это имеет
прежде всего интерес для разработчиков.EXAMPLE, если Вы создаете
MySQL из исходных текстов, вызовите CMake с
опцией
-DWITH_EXAMPLE_STORAGE_ENGINE.EXAMPLE находятся в
каталоге storage/example дистрибутива исходных текстов MySQL.
EXAMPLE, никакие файлы не создаются.
Никакие данные не могут храниться в таблицу.
Извлечения возвращают пустой результат.
mysql> CREATE TABLE test (i INT) ENGINE = EXAMPLE;
Query OK, 0 rows affected (0.78 sec)
mysql> INSERT INTO test VALUES(1),(2),(3);
ERROR 1031 (HY000): Table storage engine for 'test' doesn't have this option
mysql> SELECT * FROM test;
Empty set (0.31 sec)
Механизм хранения EXAMPLE
не поддерживает индексацию и разделение.
17.10.
Другие механизмы хранения
17.11.
Краткий обзор MySQL Storage Engine Architecture
17.11.1.
Архитектура подключаемого механизма хранения
INSTALL PLUGIN
. Например, если плагин механизма EXAMPLE называется
example и совместно используемую библиотеку называют
ha_example.so, Вы загружаете это следующим запросм:
mysql> INSTALL PLUGIN example SONAME 'ha_example.so';
Чтобы установить подключаемый механизм хранения, файл должен быть расположен
в каталоге плагинов MySQL, а пользователь, вызывающий
INSTALL PLUGIN должен иметь
привилегию INSERT для
таблицы mysql.plugin.
plugin_dir.UNINSTALL PLUGIN:
mysql> UNINSTALL PLUGIN example;
Если Вы отключаете механизм хранения, который необходим существующим
таблицам, те таблицы становятся недоступными, но будут все еще присутствовать
на диске (где применимо). Гарантируйте, что нет никаких таблиц, использующих
этот механизм хранения прежде, чем Вы отключите механизм хранения.
17.11.2.
Общий уровень базы данных сервера
| Найди своих коллег! |
Вы можете
направить письмо администратору этой странички, Алексею Паутову.
![]()